
背景故事
某次系统更新后,服务器频繁出现「服务下线-上线」的报警通知,就像家里的灯泡忽明忽暗,说明系统可能存在严重问题。
第一步:用「诊断器」Arthas 做初步诊断
1. 安装 Arthas
Arthas 是 Java 应用的「诊断器」,下载后直接运行即可(官方文档)。
2. 查看系统仪表盘
输入 dashboard 命令,就像打开汽车的仪表盘,能看到 CPU、内存等关键指标:
dashboard
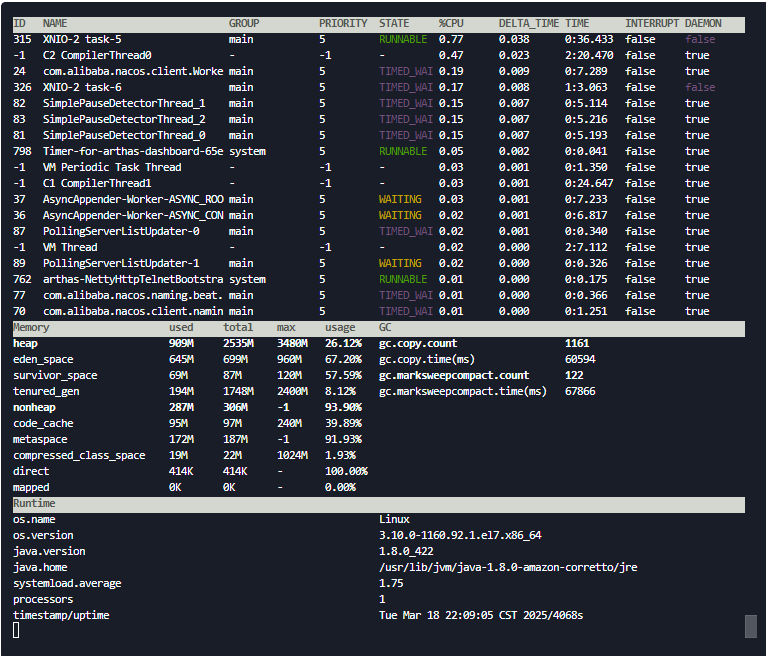
发现异常:内存使用量接近上限(好比油箱快见底了),但 CPU 正常。
3. 重点监测内存变化
输入 memory 命令,持续观察内存变化:
memory
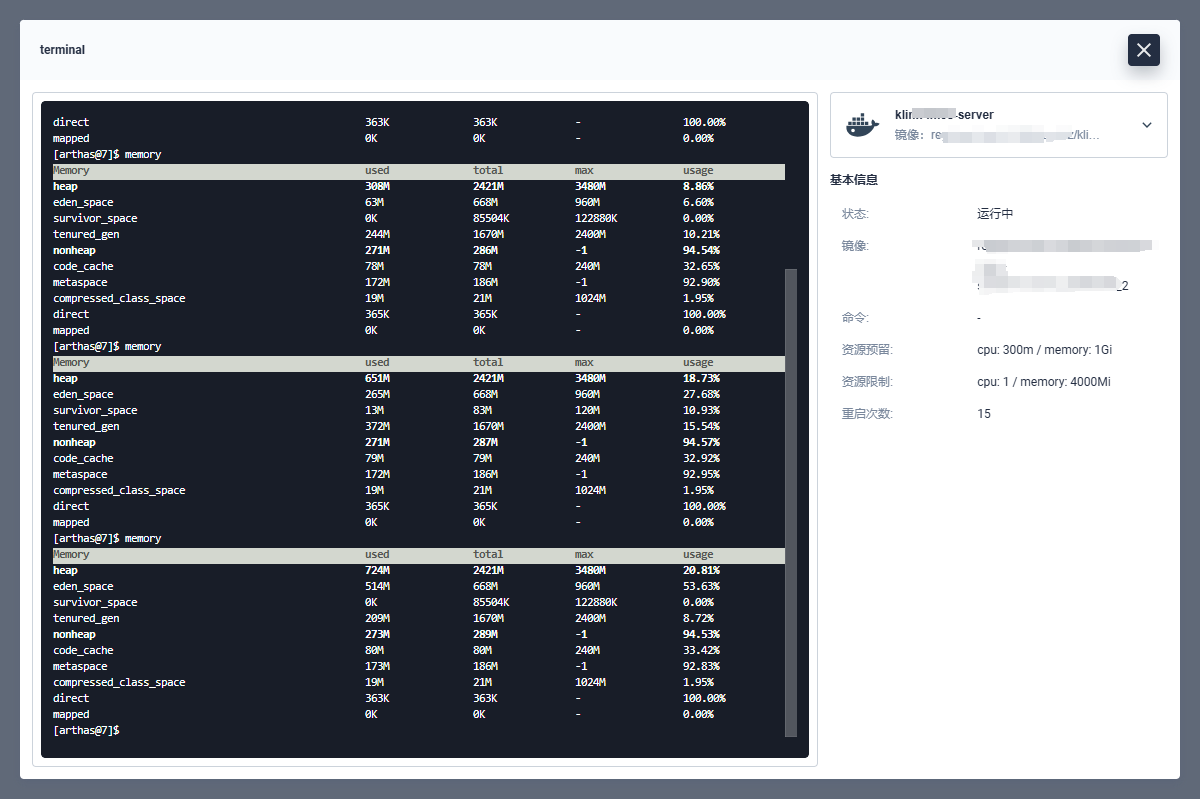
关键线索:heap(堆内存)和 eden space(新对象存放区)持续增长,像水池水位不断上涨,说明可能有内存泄漏(水桶漏水了)。
4. 给内存拍个快照
用 heapdump 命令生成内存快照(类似给漏水的水桶拍照):
heapdump arthas-output/dump.hprof
小贴士:可多次拍照,方便对比不同时间点的内存状态。
第二步:用「X光机」MAT 分析内存快照
1. 下载并打开 MAT 工具
Eclipse Memory Analyzer(MAT) 是一个快速且功能丰富的 Java 堆分析器,可帮助您查找内存泄漏并减少内存消耗。
MAT 是分析内存的「X光机」,官网下载后打开快照文件 dump.hprof。
2. 查找「大块头」对象
点击 Dominator Tree(支配树),像查账一样找出占用内存最多的对象:
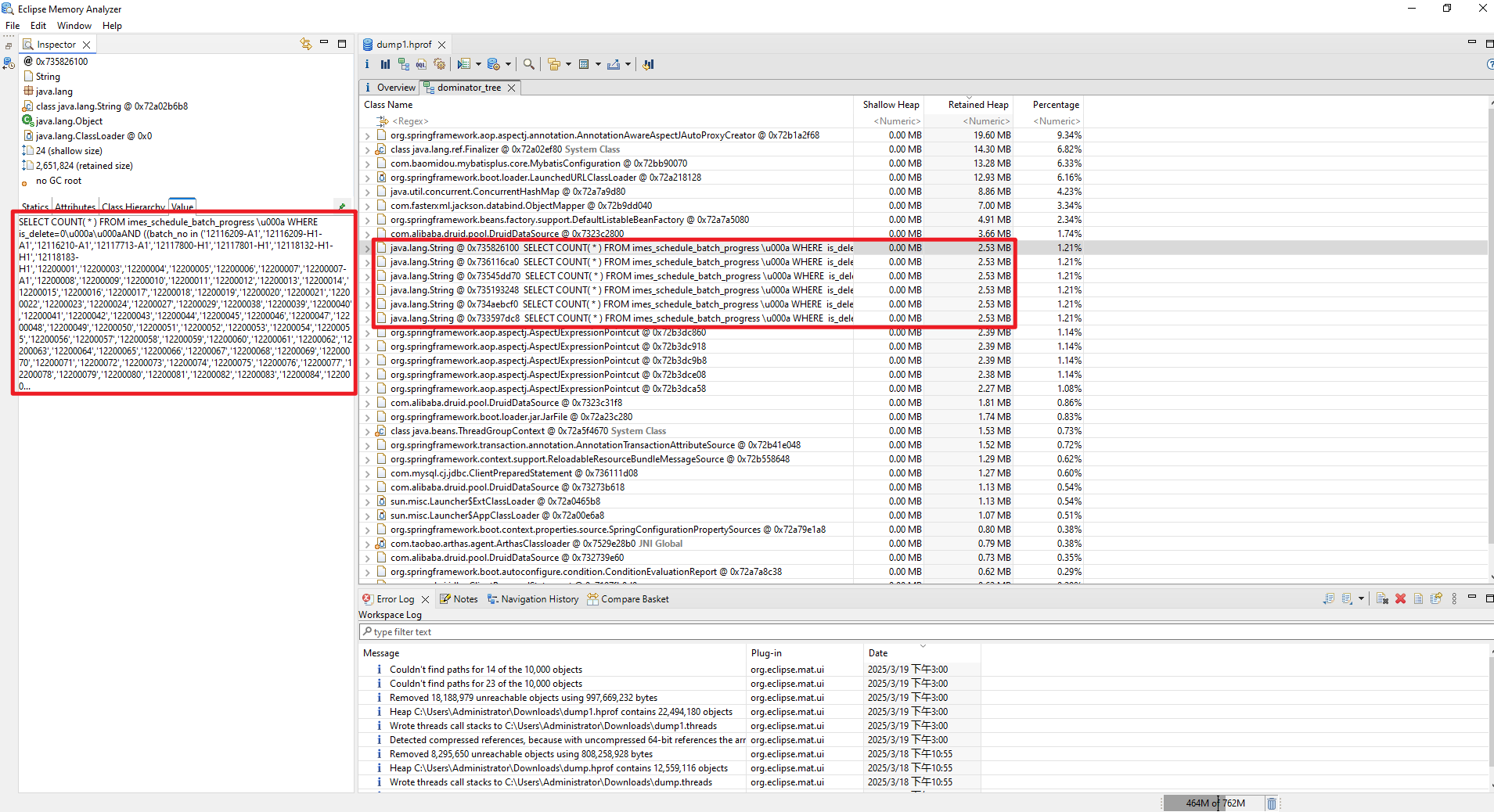
发现疑点:一个超长的 SQL 查询字符串(占用 2.53 MB),内容如下:
SELECT COUNT(*) FROM imes_schedule_batch_progress
WHERE is_delete=0
AND batch_no IN ('12116209-A1', '12116209-H1-A1'...) -- 包含 10 万个参数!
3. 风险分析
- 问题 1:频繁生成这种「巨型 SQL」会拖慢垃圾回收(就像频繁倒垃圾)。
- 问题 2:如果 SQL 被缓存长期持有,会导致内存泄漏(垃圾一直不清理)。
第三步:结合日志定位代码问题
1. 查看日志中的请求参数
在日志中发现异常请求:
{"batchNoList": []} -- 参数为空却查询了全部数据!
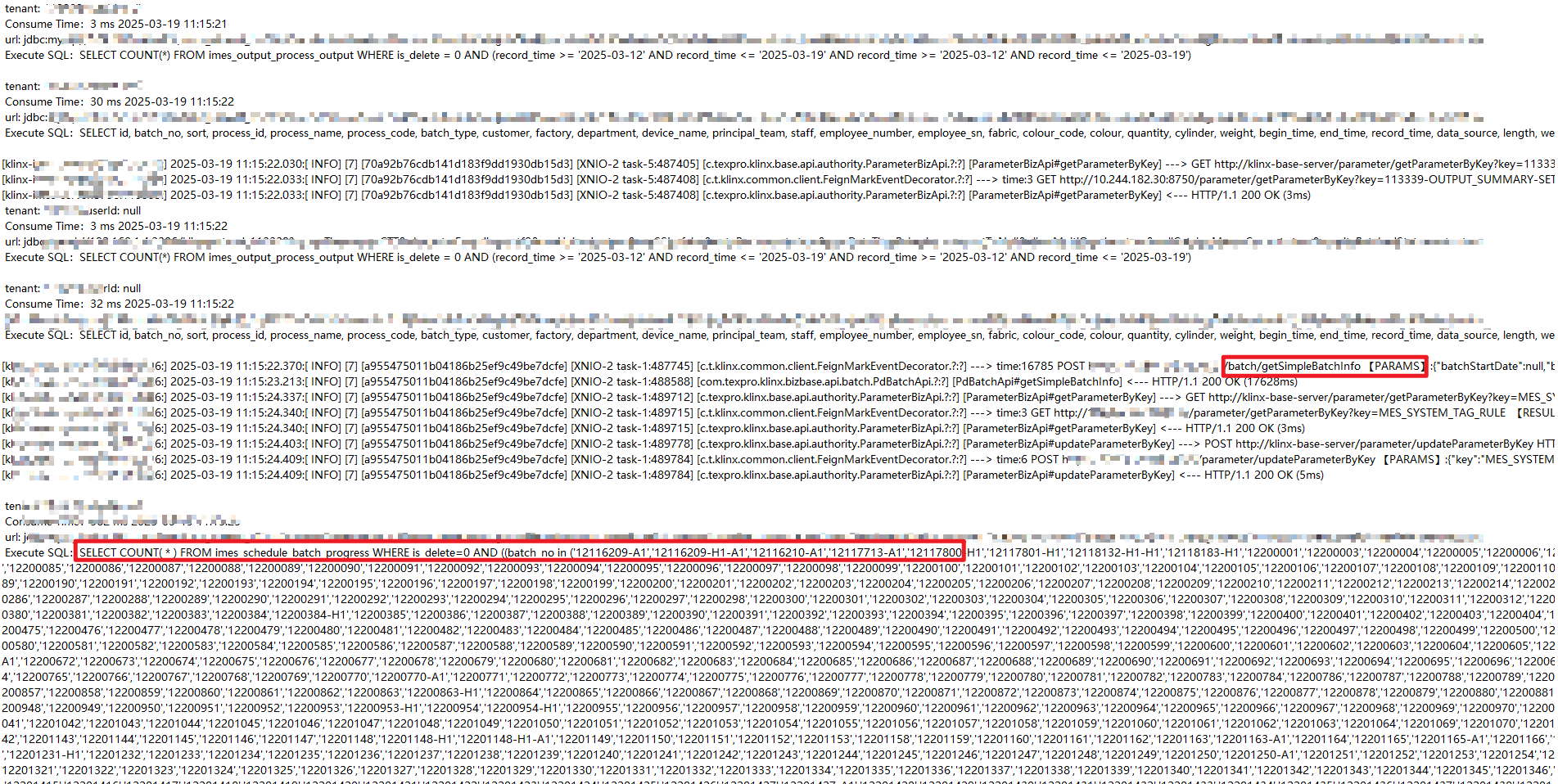
真相大白:某个接口(/batch/getSimpleBatchInfo)未校验参数,当传入空列表时,错误地查询了全量数据(10 万个批次号),拼接成超长 SQL。
第四步:修复优化
1. 代码修复
- 修复逻辑:增加参数校验,禁止空列表查询。
- 优化 SQL:改用参数化查询(类似「打包传送」数据,避免拼接字符串)。
2. 验证效果
重启服务后持续监控,内存使用量稳定,像修复了漏水的水管:
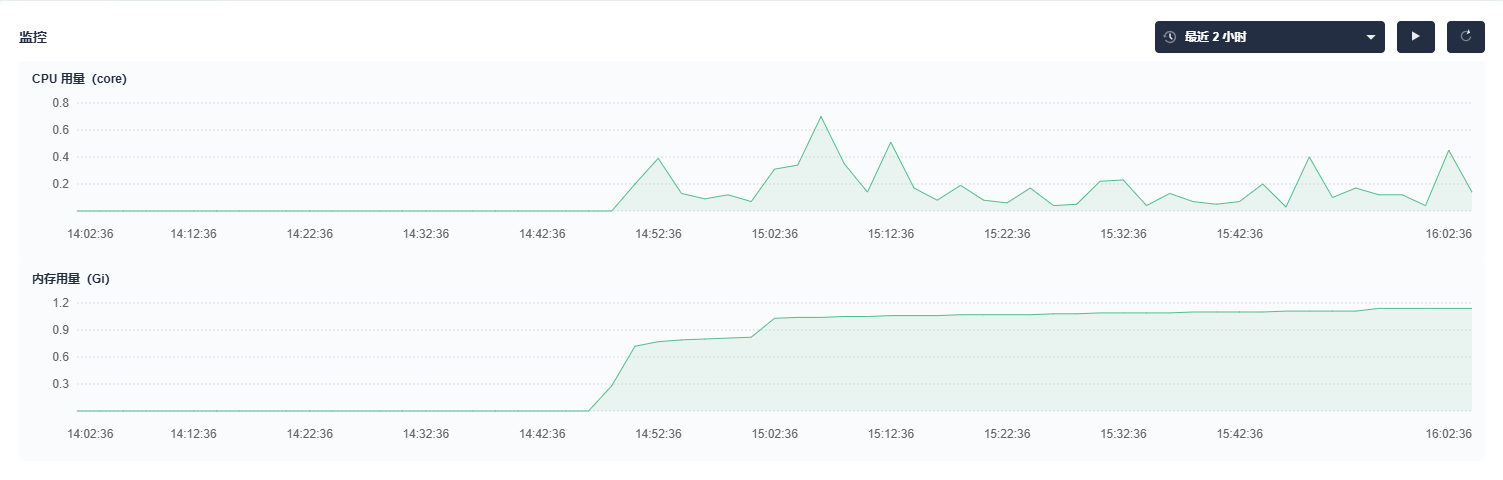
总结:OOM 排查四步法
- 仪表盘观察(
dashboard) → 看整体健康状态 - 内存监测(
memory) → 找水位上涨趋势 - 内存快照分析(
heapdump+ MAT) → 定位「大块头」对象 - 日志溯源 → 结合代码修复问题
避坑指南:
- 避免拼接超长 SQL,改用参数化查询
- 重要接口必须校验参数合法性
通过这个案例,你就像完成了一次「系统侦探」任务!后续遇到类似问题,可以按同样的流程排查。
评论