
浅谈 MySQL 全文索引
什么是全文索引?
MySQL支持使用LIKE运算符和正则表达式进行文本搜索。但是,当文本列较大并且表中的行数增加时,使用这些方法有一些限制:
- 性能问题:MySQL必须扫描整个表以根据正则表达式中的LIKE语句或模式中的模式查找确切的文本。
- 灵活搜索:使用LIKE运算符和正则表达式搜索,很难进行灵活的搜索查询,例如,查找描述包含car但不是classic的产品。
- 相关性排名:没有办法指定结果集中的哪一行与搜索字词更相关。
由于这些限制,MySQL扩展了一个非常好的功能,叫作全文搜索。从技术上讲,MySQL从启用的全文搜索列的单词中创建一个索引,并对该索引进行搜索。 MySQL使用复杂的算法来确定与搜索查询匹配的行。
以下是MySQL全文搜索的一些重要功能:
- 本地SQL类接口:使用类似SQL的语句来使用全文搜索。
- 完全动态的索引:当该列的数据发生变化时,MySQL会自动更新文本列的索引。
- 适度的索引大小:它不需要太多的内存来存储索引。
- 最后一个是,基于复杂的搜索查询快速搜索。
在 MySQL 5.6 前,仅 MyISAM 存储引擎支持全文索引,从 MySQL 5.6 开始,InnoDB 存储引擎开始支持全文索引,从 MySQL 5.7.6 内置 ngram全文解析器,开始支持中文分词。
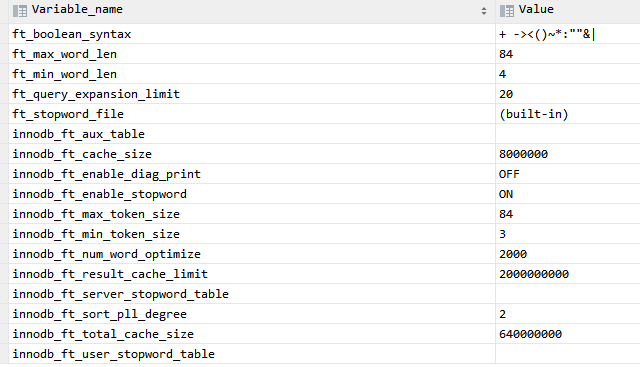
配置变量
show variables like '%ft%'
- ft_boolean_syntax:内置修饰符
+ -><()~*:""&| - ft_max_word_len:最大搜索长度,84
- ft_min_word_len:最小搜索长度,4
全文索引的原理
MySQL的全文索引是通过,倒排索引实现的。
倒排索引实际就是将要插入的文本按照相应的词进行拆分,然后额外建立一张表,存储这些出现的单词,并做出相应的统计。
怎么使用全文索引?
创建全文索引
CREATE FULLTEXT INDEX index_name ON table_name(idx_column_name,...);
俩类全文索引
- 自然语言(默认)的全文索引:通过MATCH AGAINST 传递某个特定的字符串进行检索
SELECT * FROM article WHERE MATCH (title, content) AGAINST ('顺丰快递' );
# 等价于
SELECT * FROM article WHERE MATCH (title, content) AGAINST ('顺丰快递' IN natural language MODE );
- 布尔全文索引:可以为检索的字符串增加操作符
+表示必须包含-表示必须排除>表示出现该单词时增加相关性<表示出现该单词时降低相关性*表示通配符~允许出现该单词,但是出现时相关性为负""表示短语
# 匹配度
SELECT *, AGAINST ('顺丰快递' IN natural language MODE ) as score FROM article WHERE MATCH (title, content) AGAINST ('顺丰快递' IN boolean MODE );
评论